python3 编码转换
前言
在做爬虫的时候,看到数据中有如下的数据:
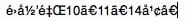
文本如下:
1 | è§æ½®å¥å®¸åº1ã2ã9ã10ã13å·æ¥¼ |
这种奇怪的字符是因为二进制码被decode为了’iso-8859-1’的编码格式,而不是正确的’utf8’
python3的编码与解码
encode (编码) : 将字符串转成二进制
语法:
1
str.encode(encoding='UTF-8',errors='strict')
ps:
- ‘UTF-8’ 中大小写不敏感,短横杠可有可无, 举个栗子: str.encode(‘uTf8’) 也可以。
- 默认使用UTF-8编码
Decode (解码) : 将二进制码转为指定编码的字符串
语法:
1
bytes.decode(encoding="utf-8", errors="strict")
出现编码错误的原因
浏览器将使用了错误的解码方式解码了二进制数据
解决办法:先使用和浏览器一样的错误编码方式编码后,再使用正确的解码方式解码。
代码
1 | a = 'è§æ½®å¥å®¸åº1ã2ã9ã10ã13å·æ¥¼' |
结果如下:

缩略图:
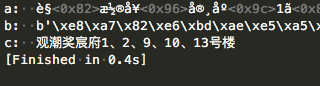
成功解码!